
科技改变生活 · 科技引领未来
科技改变生活 · 科技引领未来

来源:Python数据之道作者:阳哥大家好,我是阳哥。字典(dict)是python中的基础数据类型之一,字典的设计并不复杂,我们经常会用到这种数据类型。同时,字典也有一些比较实用的情景。学习任何一种编程语言,基础数据类型都是必备的底层基础
来源:Python数据之道
作者:阳哥
大家好,我是阳哥。
字典(dict)是 python 中的基础数据类型之一,字典的设计并不复杂,我们经常会用到这种数据类型。
同时,字典也有一些比较实用的情景。
学习任何一种编程语言,基础数据类型都是必备的底层基础,今天,我们来学习下 Python 中字典的使用。
主要内容包括:
01、基本用法
在 Python 中,字典是一种可以将相关的两个信息关联起来的操作,并且字典可存储的信息量几乎不受限制。
字典是 Python 提供的一种常用的数据结构,它用于存放具有映射关系的数据。为了保存具有映射关系的数据,Python 提供了字典,字典相当于保存了两组数据,其中一组数据是关键数据,被称为 key;另一组数据可通过 key 来访问,被称为 value。
创建字典
字典是以 key、value 的形式创建的。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
一般情况下,字典的创建可以有以下几种方式:
# 创建一个空的字典 my_dict1 = {} # 创建 key 值为整数的字典 my_dict2 = {1: 'apple', 2: 'ball'} # 创建 key 值为 string 的字典 my_dict3 = {'name1': 'apple', 'name2': 'ball'} # 创建 key 值为 数字 和 string 混合的字典 my_dict4 = {'name': 'apple', 1: [2, 4, 3]} # 用 dict() 函数创建字典 my_dict5 = dict({1:'apple', 2:'ball'}) # 以元组的形式组成序列创建字典 my_dict6 = dict([(1,'apple'), (2,'ball')]) print('my_dict1:', my_dict1) print('my_dict2:', my_dict2) print('my_dict3:', my_dict3) print('my_dict4:', my_dict4) print('my_dict5:', my_dict5) print('my_dict6:', my_dict6) 结果如下:
my_dict1: {} my_dict2: {1: 'apple', 2: 'ball'} my_dict3: {'name1': 'apple', 'name2': 'ball'} my_dict4: {'name': 'apple', 1: [2, 4, 3]} my_dict5: {1: 'apple', 2: 'ball'} my_dict6: {1: 'apple', 2: 'ball'} 也可以通过下面的方式来创建空白字典
# 创建空白字典的另一种方式 my_dict7 = dict() # print('my_dict7:', my_dict7) my_dict7 结果如下:
{} 获取字典中的元素
通过 key 来获取 value
获取字典中的元素,可以直接通过 key 值来获取对应的 value,如下:
my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3]} print(my_dict8['name']) print(my_dict8.get('name')) 结果如下:
John John 请注意,如果字典的key值中没有该元素,则不能获取相应的 value,这种情况下产生错误。
print(my_dict8['name1']) 结果如下:
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) in ----> 1 print(my_dict8['name1']) KeyError: 'name1' 通过 value 来获取 key
通过 value 来获取 key 值,在 Python 中并没有提供直接的方法,我们可以通过自定义函数来实现,如下:
def get_keys(d, value): return [k for k,v in d.items() if v == value] 函数中,d 是字典。
在字典中修改或添加元素
在字典中,可以修改已有 key 对应的 value 值,或者添加新的 key-value 键值对数据,如下:
my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3]} # 修改已有 key 对应的 value 的值 my_dict8['age'] = 98 # 添加新的 key-value 数据组 my_dict8['gender'] = 'man' my_dict8 结果如下:
{'name': 'John', 'age': 98, 1: [2, 4, 3], 'gender': 'man'} 从字典中删除元素
从字典中删除元素,或者删除整个字典,有以下一些方式。
pop() 方法
移除字典数据pop()方法的作用是:删除指定给定键所对应的值,返回这个值并从字典中把它移除。
# 使用 pop()方法来删除 my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3]} my_dict8.pop('age') my_dict8 结果如下:
{'name': 'John', 1: [2, 4, 3]} del 方法
# 使用 del 方法来删除 my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3]} del my_dict8['name'] my_dict8 结果如下:
{'age': 25, 1: [2, 4, 3]} popitem() 方法
# 使用 popitem()方法来删除 my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man', 'school': 'UCI', 'city': 'NewYork'} my_dict8.popitem() my_dict8 结果如下:
{'name': 'John', 'age': 25, 1: [2, 4, 3], 'gender': 'man', 'school': 'UCI'} 关于 popitem() 方法:
在Python 3.5版本以及之前的时候,使用 popitem() 可能是随机删除的,但我曾经用的 Python3.6版本,好像不是随机删除的,是删除的最后一项。
从 Python 3.7 版本开始,使用 popitem() 方法是删除最后一项,因为字典默认是记住了顺序的:
Ordered dictionaries are just like regular dictionaries but have some extra capabilities relating to ordering operations.
They have become less important now that the built-in dict class gained the ability to remember insertion order (this new behavior became guaranteed in Python 3.7).
另外,我查阅了一下 Python3.7 版本中的描述,如下:
popitem()
Remove and return a (key, value) pair from the dictionary. Pairs are returned in LIFO order.
popitem() is useful to destructively iterate over a dictionary, as often used in set algorithms. If the dictionary is empty, calling popitem() raises a KeyError.
Changed in version 3.7: LIFO order is now guaranteed. In prior versions, popitem() would return an arbitrary key/value pair.
https://docs.python.org/3/library/stdtypes.html#mapping-types-dict
在 Python3.7 版本中,是按照 LIFO 的原则进行删除的,是有序进行删除的。
LIFO (Last-in, first-out)即后进来的先删除(也可理解为按后面往前的排序进行删除)
clear()方法
clear()方法是用来清除字典中的所有数据,因为是原地操作,所以返回 None(也可以理解为没有返回值)
# 使用 clear()方法来清空字典中的所有数据,返回的是一个空字典 my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} my_dict8.clear() my_dict8 结果如下:
{} del 方法
del 方法可以删除字典中指定 key 值的内容。
另外, del 可以删除整个字典,与 clear() 方法的清空字典中所有数据是不一样的。演示如下:
使用 del方法是删除字典中指定 key 值对应的内容
# 使用 del方法是删除字典中指定 key 值对应的内容 my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} del my_dict8['age'] my_dict8 结果如下:
{'name': 'John', 1: [2, 4, 3], 'gender': 'man'} 使用 del方法是删除整个字典,删除后,再运行程序,会报错误
# 使用 del方法是删除整个字典,删除后,再运行程序,会报错误 my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} del my_dict8 my_dict8 结果如下:
--------------------------------------------------------------------------- NameError Traceback (most recent call last) in 4 del my_dict8 5 ----> 6 my_dict8 NameError: name 'my_dict8' is not defined 字典内置函数&方法
Python字典包含了以下内置函数:
序号函数及描述len(dict)计算字典元素个数,即键的总数。str(dict)输出字典可打印的字符串表示。type(variable)返回输入的变量类型,如果变量是字典就返回字典类型。
len(), str(), type() 函数
my_dict6 = dict([(1,'apple'), (2,'ball')]) my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} print(len(my_dict8)) print(str(my_dict6)) print(type(my_dict8)) 结果如下:
4 {1: 'apple', 2: 'ball'} 'dict'> Python字典包含以下一些方法:
函数函数描述clear()删除字典内所有元素,返回空字典copy()返回一个字典的浅复制fromkeys(seq[, val])创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值get(key, default=None)返回指定键的值,如果值不在字典中返回 default 值items()以列表返回可遍历的(键, 值) 元组数组keys()以列表返回一个字典所有的键setdefault(key, default=None)和 get()类似, 但如果键不存在于字典中,将会添加键并将值设为 defaultupdate(dict2)把字典 dict2 的键/值对更新到 dict里values()以列表返回字典中的所有值pop(key[,default])删除字典给定键 key 所对应的值,返回值为被删除的值。key 值必须给出。否则,返回 default值。popitem()随机返回并删除字典中的一对键和值。Python 3.6及以后版本,以 LIFO 的原则进行删除的,是有序进行删除的。
clear(), get(), pop(), popitem() 等在上面已介绍的方法,这里不做重复,仅演示其他方法的使用。
copy, keys, values, items 方法
my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} print('copy:', my_dict8.copy()) print('keys:', my_dict8.keys()) print('values:', my_dict8.values()) print('items:', my_dict8.items()) 结果如下:
copy: {'name': 'John', 'age': 25, 1: [2, 4, 3], 'gender': 'man'} keys: dict_keys(['name', 'age', 1, 'gender']) values: dict_values(['John', 25, [2, 4, 3], 'man']) items: dict_items([('name', 'John'), ('age', 25), (1, [2, 4, 3]), ('gender', 'man')]) update 方法
通过 update 方法,可以更新字典的数据内容:
my_dict6 = {'name': 'Lemon', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} my_dict8.update(my_dict6) my_dict8 结果如下:
{'name': 'Lemon', 'age': 25, 1: [2, 4, 3], 'gender': 'man'} fromkeys 方法
fromkeys()方法的演示如下:
请注意,该结果与 zip() 方法之后的结果是不一样的。
seq = ['name', 'age', 'city'] value = ['Lemon', 18, 'cs'] my_dict9 = dict.fromkeys(seq, value) my_dict9 结果如下:
{'name': ['Lemon', 18, 'cs'], 'age': ['Lemon', 18, 'cs'], 'city': ['Lemon', 18, 'cs']} zip()方法
seq = ['name', 'age', 'city'] value = ['Lemon', 18, 'cs'] my_dict10 = dict(zip(seq, value)) my_dict10 结果如下:
{'name': 'Lemon', 'age': 18, 'city': 'cs'} setdefault 方法
dict.setdefault(key, default=None)
该方法接收两个参数,第一个参数是健的名称,第二个参数是默认值。
假如字典中不存在给定的键,则把默认值赋值给对应的value,并返回默认值;
反之,不修改value,只返回value。
my_dict8 = {'name': 'John', 'age': 25 , 1: [2, 4, 3], 'gender': 'man'} print('字典中存在的key,返回对应value:', my_dict8.setdefault('age', 0)) print('字典中不存在的key,返回默认值:', my_dict8.setdefault('age1', 0)) 结果如下:
字典中存在的key,返回对应value: 25 字典中不存在的key,返回默认值: 0 此外,还可以用 setdefault() 方法统计一个列表里单词出现的次数:
# 用 setdefault() 方法统计一个列表里单词出现的次数 strings = ('Lemon', 'kitten', 'Lemon', 'Lemon', 'lemon_zs', 'Lemon', 'Lemon', 'lemon_zs') counts = {} for kw in strings: counts[kw] = counts.setdefault(kw, 0) + 1 counts 结果如下:
{'Lemon': 5, 'kitten': 1, 'lemon_zs': 2} 02、字典推导式(dict comprehension)
字典推导式的一般表达式如下:
{key: value for (key, value) in iterable}
有些用法与列表推导式是类似的,可以参考下面的内容:
用字典推导式的方法创建字典:
my_dict01 = {x: x*x for x in range(6)} my_dict01 结果如下:
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25} 通过两个list创建字典:
keys = ['name', 'age', 'city'] values = ['Lemon', 18, 'cs'] my_dict02 = {k:v for (k,v) in zip(keys,values)} my_dict02 结果如下:
{'name': 'Lemon', 'age': 18, 'city': 'cs'} 在特定条件下,用字典推导式的方法创建字典:
my_dict03 = {x: x*x for x in range(10) if x%2==0} my_dict03 结果如下:
{0: 0, 2: 4, 4: 16, 6: 36, 8: 64} 03、嵌套型字典
什么是嵌套型的字典
字典是以 key、value 的形式创建的, 而嵌套型的字典有一个特征,就是 key 对应的 value 值也可以是一个字典。最简洁的嵌套型字典如下:
d = {key1 : {key3 : value3}, key2 : {key4 : value4} } 创建一个嵌套型字典
nested_dict01 = {1: {'name':'Lemon', 'age': '18', 'city':'cs'}, 2: {'name':'Lemon_zs', 'age': '18', 'city':'changsha'}} nested_dict01 结果如下:
{1: {'name': 'Lemon', 'age': '18', 'city': 'cs'}, 2: {'name': 'Lemon_zs', 'age': '18', 'city': 'changsha'}} 上述的嵌套型字典中,字典第一层的 key 分别是 1 和 2, 而他们对应的 value 值又是都是字典, 里面的字典的 key 都是 "name", "age" 和 "city", 但对应的 value 不一样。
从嵌套型字典中获取元素
从嵌套型字典中获取元素,跟从 list, 以及数组中获取元素时有些类似的。
嵌套型字典 用 [] 进行不同层级元素的获取。
nested_dict01 = {1: {'name':'Lemon', 'age': '18', 'city':'cs'}, 2: {'name':'Lemon_zs', 'age': '18', 'city':'changsha'}} print(nested_dict01[1]['name']) print(nested_dict01[2]['city']) 结果如下:
Lemon changsha 修改嵌套型字典的元素 (更改、增加或删除元素)
针对嵌套型字典,同样是可以更新、增加或删除元素的.
增加一个空的字典
nested_dict01 = {1: {'name':'Lemon', 'age': '18', 'city':'cs'}, 2: {'name':'Lemon_zs', 'age': '18', 'city':'changsha'}} # 增加一个空的字典 nested_dict01[3] = {} nested_dict01 结果如下:
{1: {'name': 'Lemon', 'age': '18', 'city': 'cs'}, 2: {'name': 'Lemon_zs', 'age': '18', 'city': 'changsha'}, 3: {}} 修改或增加新的元素
# 修改元素内容 nested_dict01[2]['age'] = '26' # 增加新的元素 nested_dict01[3]['name'] = 'zws' nested_dict01 结果如下:
{1: {'name': 'Lemon', 'age': '18', 'city': 'cs'}, 2: {'name': 'Lemon_zs', 'age': '26', 'city': 'changsha'}, 3: {'name': 'zws'}} 在嵌套型字典中直接添加一个字典
# 在嵌套型字典中直接添加一个字典 nested_dict01[5]={'name': 'rx', 'age':'3', 'city':'ly'} nested_dict01 结果如下:
{1: {'name': 'Lemon', 'age': '18', 'city': 'cs'}, 2: {'name': 'Lemon_zs', 'age': '26', 'city': 'changsha'}, 3: {'name': 'zws'}, 5: {'name': 'rx', 'age': '3', 'city': 'ly'}} 删除某个具体元素内容
# 删除某个具体元素内容 del nested_dict01[5]['city'] nested_dict01 结果如下:
{1: {'name': 'Lemon', 'age': '18', 'city': 'cs'}, 2: {'name': 'Lemon_zs', 'age': '26', 'city': 'changsha'}, 3: {'name': 'zws'}, 5: {'name': 'rx', 'age': '3'}} 删除嵌套字典里面的某个字典
# 删除嵌套字典里面的某个字典 del nested_dict01[5] nested_dict01 结果如下:
{1: {'name': 'Lemon', 'age': '18', 'city': 'cs'}, 2: {'name': 'Lemon_zs', 'age': '26', 'city': 'changsha'}, 3: {'name': 'zws'}} 通过 for 循环来获取嵌套字典内的元素
for main_id, main_info in nested_dict01.items(): print('nmain id: ', main_id) for key in main_info: print(key+':', main_info[key]) 结果如下:
main id: 1 name: Lemon age: 18 city: cs main id: 2 name: Lemon_zs age: 26 city: changsha main id: 3 name: zws 用 pprint 输出嵌套型字典
用 pprint 可以使字典显示层次更清晰,需要安装 pprint,安装命令如下:
pip install pprint
演示如下:
# 需要安装 pprint # pip install pprint # pprint 可以使字典显示层次更清晰 import pprint menu = {'dinner':{'chicken':'good','beef':'average', 'vegetarian':{'tofu':'good', 'salad':{'caeser':'bad', 'italian':'average'}}, 'pork':'bad'}} pprint.pprint(menu) 结果如下:
{'dinner': {'beef': 'average', 'chicken': 'good', 'pork': 'bad', 'vegetarian': {'salad': {'caeser': 'bad', 'italian': 'average'}, 'tofu': 'good'}}} 嵌套型字典的一些用途
可能有些疑惑,字典嵌套这么多层,在哪些地方可以用呢?
这里分享一个用途。嵌套型字典,经常在机器学习中的决策树算法中涉及到。
比如下面的 menu, 是一个字典。它也可以用树的形式显示出来,这在 决策树中会经常用到。
menu = {'dinner':{'chicken':'good','beef':'average', 'vegetarian':{'tofu':'good', 'salad':{'caeser':'bad', 'italian':'average'}}, 'pork':'bad'}} 示例:
from sklearn.tree import DecisionTreeClassifier, export_graphviz from sklearn import tree from sklearn.datasets import load_wine from IPython.display import SVG from graphviz import Source from IPython.display import display # load dataset data = load_wine() # feature matrix X = data.data # target vector y = data.target # class labels labels = data.feature_names # print dataset description # print(data.DESCR) estimator = DecisionTreeClassifier() estimator.fit(X, y) graph = Source(tree.export_graphviz(estimator, out_file=None , feature_names=labels, class_names=['0', '1', '2'] , filled = True)) display(SVG(graph.pipe(format='svg'))) 可视化效果如下:
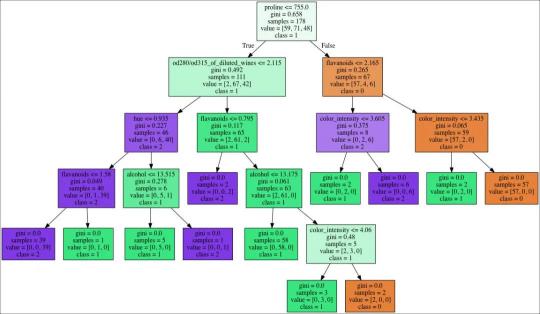
04 小结
以上就是 python 中关于字典使用的基础内容,在实践中,咱们还会大量应用到字典。相对来说,嵌套字典会比较复杂些。当我们熟练使用字典的基本方法时,还是可以应对这些问题的。
有时候,也会有一些比较独特的字典,比如 key-value 键值对中的 value 是 pandas 中的 dataframe ,其基础原理,一些常用的方法还是一样的。

丁夕