
科技改变生活 · 科技引领未来
科技改变生活 · 科技引领未来

信道编码方案是5GNR接入技术的基本问题之一。作为NR-eMBB方案的候选方案,提出了三种信道编码方案,即Polarcode,Turbocode和LDPCcode。在本文中,主要接受华为给出的三种信道编码方案的性能比较结果。Polarcod
信道编码方案是5G NR接入技术的基本问题之一。作为NR-eMBB方案的候选方案,提出了三种信道编码方案,即Polar code, Turbo code 和 LDPC code。在本文中,主要接受华为给出的三种信道编码方案的性能比较结果。
Polar code是基于信道极化的可证明容量实现码。Polar code的构造方法在R1-164309和
R1-167209中有详细介绍,由于Polar code的嵌套结构,Polar code很容易支持任意的编码速率和信息长度。除了简单的SC解码器外,CA-SCL解码器也可以达到很好的性能。
LDPC码有两种方法。首先,为了支持多速率,需要准备许多LDPC码的协议,以降低在发送端过多的穿孔所带来的复杂性,同时还要考虑这些协议的存储。第二,采用嵌套矩阵,支持多速率。然而,嵌套矩阵具有较小的提升尺寸,导致高编码/解码复杂度和性能下降。另外,对于这两种方法,PCM:parity check matrix(奇偶校验矩阵)应设计为简单的速率自适应和HARQ方案。
这里对极性码和LDPC码的性能进行了比较,并在eMBB情况下增加了LTE-turbo性能,以供参考。先看两张模拟参数表:
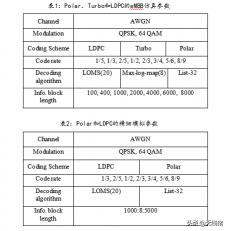
根据这两个模拟假设,模拟了一组富块长度和码率组合。Polar code的译码算法是CA-SCL32。对于LDPC,译码算法采用了20次迭代的最小和分层,这里采用了Samsung在R1-164812中LDPC的奇偶校验矩阵和相应的最小和分层译码算法的归一化值。对于turbo,它是max-log-map,比例=0.75,迭代次数是8。在模拟过程中,对于所有信息长度的Turbo码和LDPC码不添加CRC位,对于信息长度为100和400的Polar code,添加8位CRC位。对于Polar code的其他情况,使用24位CRC。
调制 Modulation = {QPSK}
Modulation = {64 QAM}
对于R1-164812中给出的11n-like 嵌套矩阵,通过缩短和屏蔽1/3奇偶校验矩阵,可以获得高于1/3的编码率。因此,对于较高的编码速率(例如1/2和2/3),性能损失比编码速率1/3的性能损失更大。
从图1和图2可以看出,在编码速率为1/3时,与Polar相比,性能损失约为0.2-0.4dB。然而,对于编码率1/2和2/3,损耗大约为1dB。
对于低于1/3的编码率,之前只是从1/3奇偶校验矩阵中重新传输部分编码比特。因此,对于编码率低于1/3的情况,将没有编码增益。
此外,对于QPSK和64-QAM,LDPC和Turbo码的性能损失与Polar码的性能损失趋势相同。
结论是:Polar 和Turbo码在所有码率下都优于11n-like-LDPC码。Polar 在所有码率和块长上都比Turbo码和11n-like-LDPC码有更好的性能。
细粒度性能比较
Modulation = {QPSK}
为了支持类似于LTE中Turbo粒度的细粒度,应该仔细设计嵌套矩阵,以避免某些代码长度导致性能急剧下降。如图3所示,这些糟糕的性能点往往发生在低编码率区域。对于极高的编码速率区域,LDPC code有大约0.2-0.4dB的性能损失和更多的波动点。
下面给出了更多的细粒度模拟结果。
从图4、图5和图6可以看出,在编码率为1/3时,存在一些比编码率为5/6时性能损失更大的缺点。然而,在编码率为5/6时,有更多的波动点。在图5中,与Polar码相比,LDPC码在所有信息长度上都有大约1dB的性能损失。
结论是:为了支持细粒度,LDPC可能有一些性能急剧下降的缺点,这意味着应该仔细设计缩短和穿孔方案。Polar码没有这样的问题。
关于Polar解码器的设计,有如下方案:
SC list (SCL) decoding :SC解码器通过在每个解码步骤保持候选列表来概括SC解码,其中列表大小为L。在列表解码期间,保留具有最佳路径度量的L条路径。最后,选择具有最佳路径度量的路径作为最终解码结果。
SC stack (SCS) decoding:stack译码器是SC译码器的另一个推广,与SCL类似,它在译码过程中产生了许多候选码。不同之处在于,SCS不是保持所有候选路径的长度相同,而是开发具有最可能路径的路径。如果某个长度的路径数达到L,则从堆栈中删除所有较短的路径。当L被设置为与SCL中的相同并且使用足够大的Q时,SCS具有与SCL相同的性能。
由于分割率很低,解码路径通常不需要推送到队列或从队列中弹出,这意味着一种高度并行的内存组织和高效率的PE利用率。在这种情况下,解码路径的行为与独立SC解码器相同。这种类型的多个路径可以并行开发,如下图所示
在框图中,有八个并行处理单元,每个并行处理单元包含用于存储LLR表的RAM单元和用于计算LLR的处理元件(PE: processing element)。如果处理单元到达一个分割点,新生成的两条路径将被推送到优先级队列中。同时,缓冲器中的路径将被填充到空出的处理单元中以进行进一步处理。随后,将弹出一条具有最佳路径度量的路径来填充路径缓冲区。这样,在等待队列操作的结果时,PE将永远不会空闲。
极Polar解码器最消耗的区域是存储路径度量和LLR表,它们占据了大约80%的RAM。华为给出的数据证明,在适当的重新设计下,它们可以大大减少。
新的路径度量:可以利用先验知识和后验知识来定义一个在PPD(Prioritized parallel decoder)中更有效的路径度量。该先验知识用于补偿路径扩展过程中的平均代价。改进的路径度量不仅加快了译码速度,而且大大减小了所需的优先级队列大小Q。
LLR表存储:在SCL中,LLR表是最消耗空间的部分。与SCL需要L个并行处理单元(包括RAM和PE)不同,PPD只需要 l个并行处理单元(l

李书